1. Todis 和 Tair
- Todis 是 Redis On ToplingDB,兼容 Redis 的 “外存版 Redis” 分布式数据库,可以使用 Redis 客户端存取、操作数据
- Todis 已在 github 开源,用户可以自己编译(社区版)
- Tair 是阿里云的 “外存版 Redis”,同样兼容 Redis,可以使用 Redis 客户端存取、操作数据
2. 为什么与 Tair 对比
- 因为市面上有很多种 “外存版 Redis”,而阿里云 Tair 是其中的最先进代表
- 我们的内测版是运行在阿里云之上的,用户很容易重现测试结果
3. 相比 Tair,Todis 有什么优势?
Todis 使用了多种先进技术,资源利用率更高,即便使用规格更低的机器,无论是读还是写,性能都远远超过 阿里云的 Tair。
在测试中,Todis 和 Tair 读写相同原始数据,用同样的 Redis 客户端程序,同样的命令行选项,进行性能对比测试。
4. 测试数据:Wikipedia 英文版
| 总尺寸 | 109 GB |
|---|---|
| 总条数 | 3850 万条 |
| 平均长度 | 2.8 KB |
5. 全量数据对比测试结果
在各个测试中,Todis 使用的云主机规格均低于 Tair,具体规格在下面图示中给出。
对于 strings 类型,测试顺序写、随机写、顺序读与随机读性能。
- 写数据使用多线程并发 mset,每次写 32 条数据,相比 set 每次写一条数据,减小了网络往返开销
- 读数据使用多线程并发 mget,每次读 32 条数据,相比 get 每次读一条数据,减小了网络往返开销
- 写完数据之后,读取数据之前,不执行手动 compact,这样更接近真实的业务场景
Strings 类型测试使用工具分别向 Todis 和 Tair 中写入测试数据(Strings 类型)数据,然后读。
每组写测试相互独立,读测试使用写测试中写入的数据,其中随机读测试以循环读的方式取第三轮结果。
下面以条形图来显示平均速度,以折线图来显示瞬时速度。
5.1 平均速度
平均速度的条形图简单直观,可以从中清楚地看到对比结果。
5.1.1 写数据
Todis 的写性能远高于 Tair,这是因为 Todis 利用了弹性分布式 Compact,将 Compact 负载转移到专用的 Compact 计算集群,从而:
- Todis 结点只需要低规格的机器即可实现很高的性能,所以使用内存型结点(如果有“密集内存型”结点就更好了)
- Compact 是计算密集型的,内存需求不高,其结点可以使用“计算型”,甚至“密集计算型”结点
- Compact 集群是多用户多实例共享的,从而可以对多用户多实例的 Compact 负载进行平峰错谷,提高资源利用率
- 如果一段时间内没有执行写操作,就没有 Compact
- 类似 Tair 这样的 DB 需要为 Compact 预留算力(需要使用高规格的结点)
- Todis DB 结点不需要为 Compact 预留算力
- Compact 集群的单个结点不需要长期稳定运行,可以随时终止,从而可以使用“空闲算力”,降低总体成本
- 大厂的“空闲算力”总是有的,需要的是找到可以利用这些“空闲算力”的应用
- 云厂商的“空闲算力”非常便宜,最低可以到正常价格的一折
先看 顺序写:顺序写的写放大较低,所以性能更高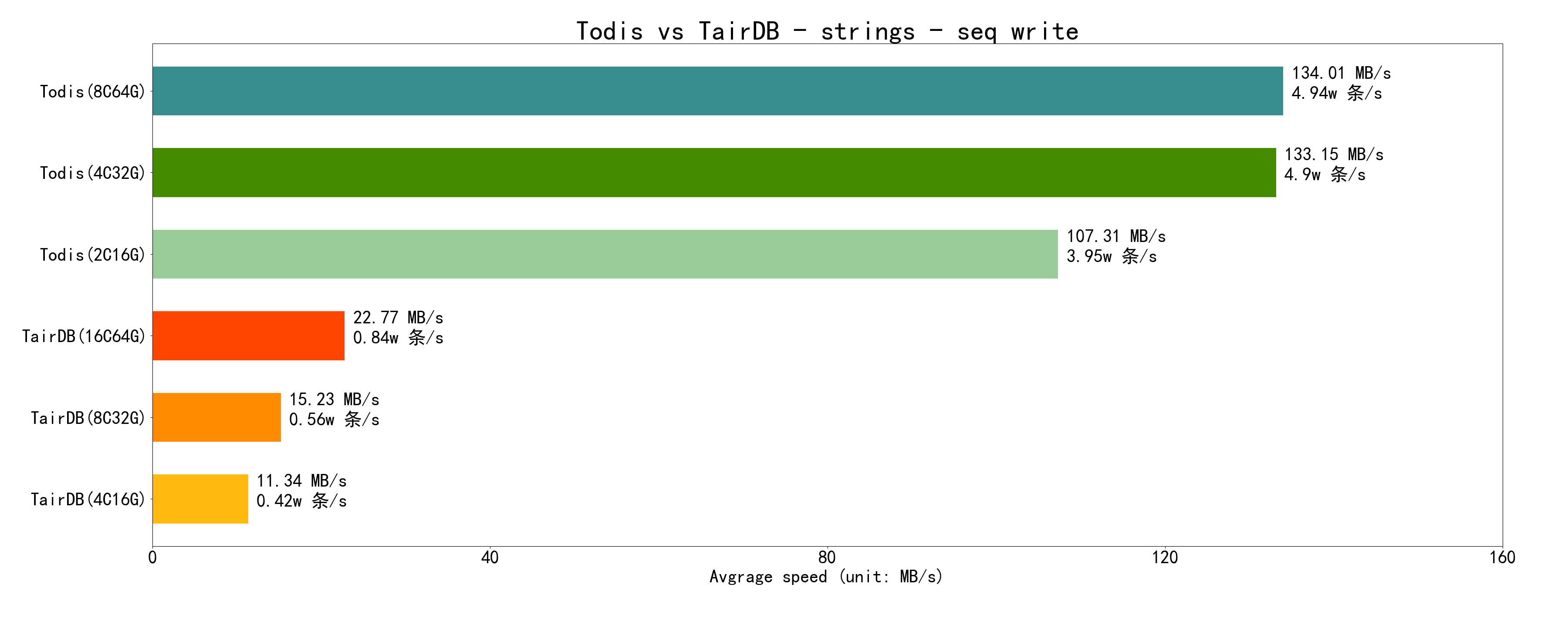
再看 随机写:随机写的写放大较低,所以性能较低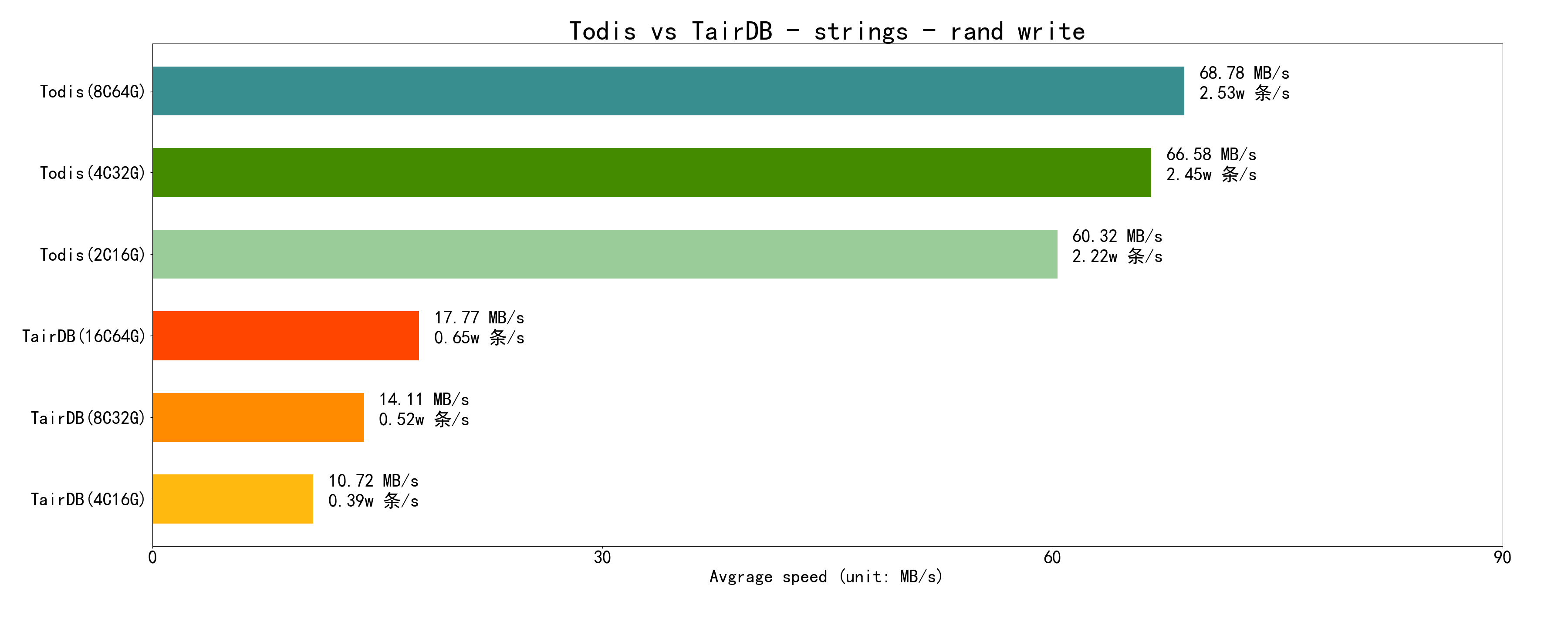
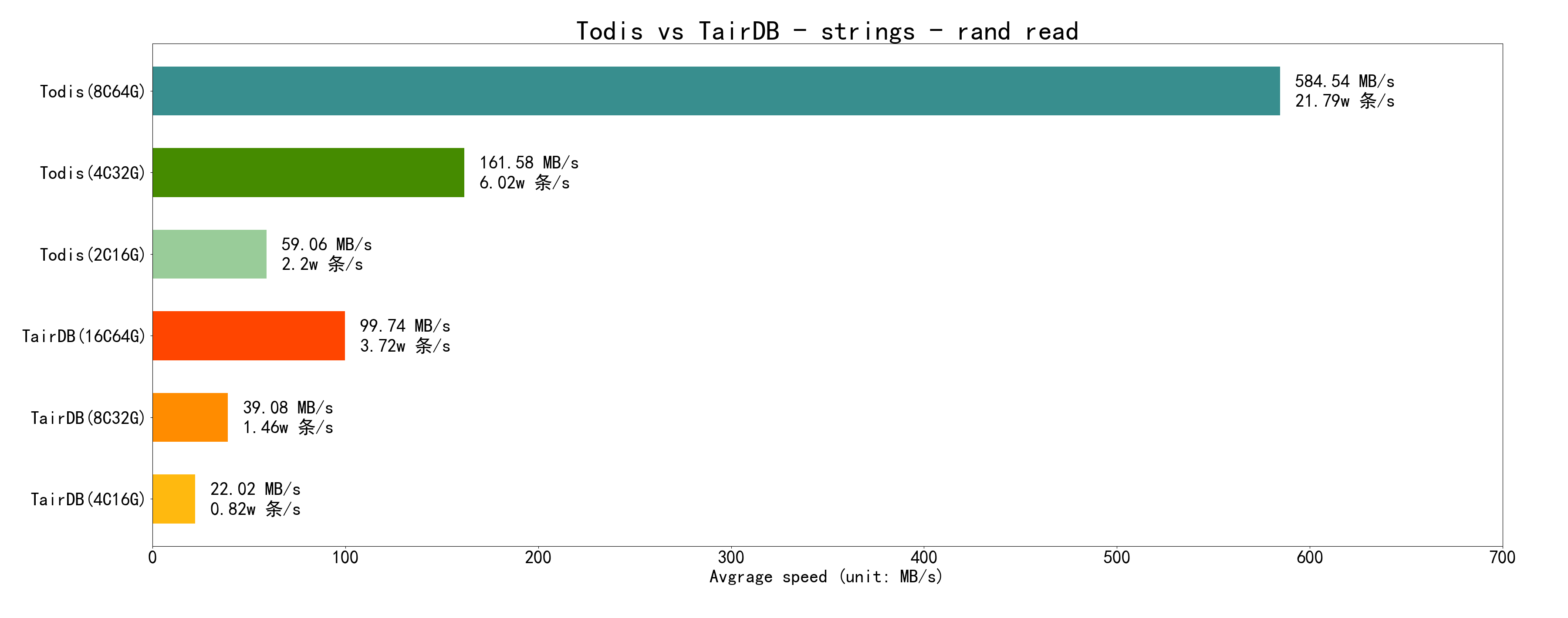
5.1.2 读数据
Todis 的读性能也远高于 Tair,因为 Todis 使用了“可检索内存压缩”技术
- 直接在压缩的数据上执行搜索,大大提升了内存利用率
- 这种压缩算法的读性能非常好,所以对 CPU 的需求很低
读数据用的是 mget,取的是第二轮读的平均速度,即相对稳定后的速度
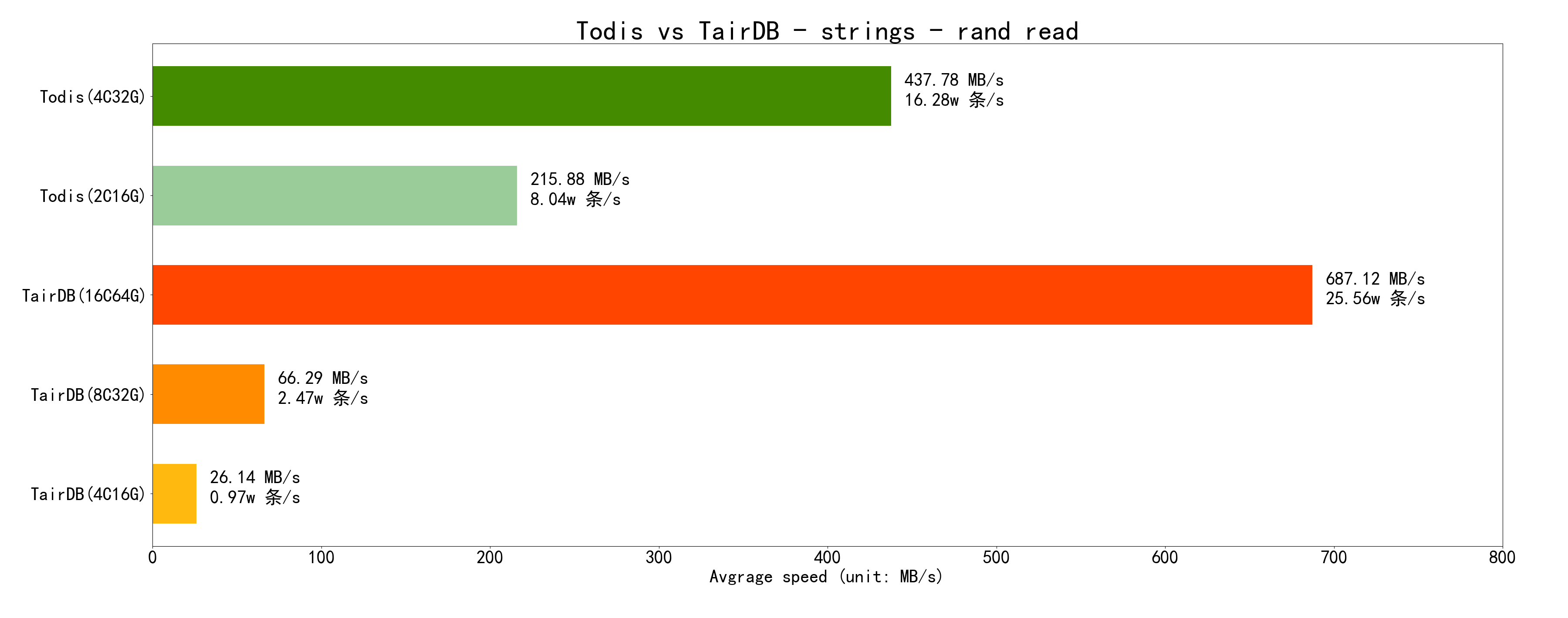
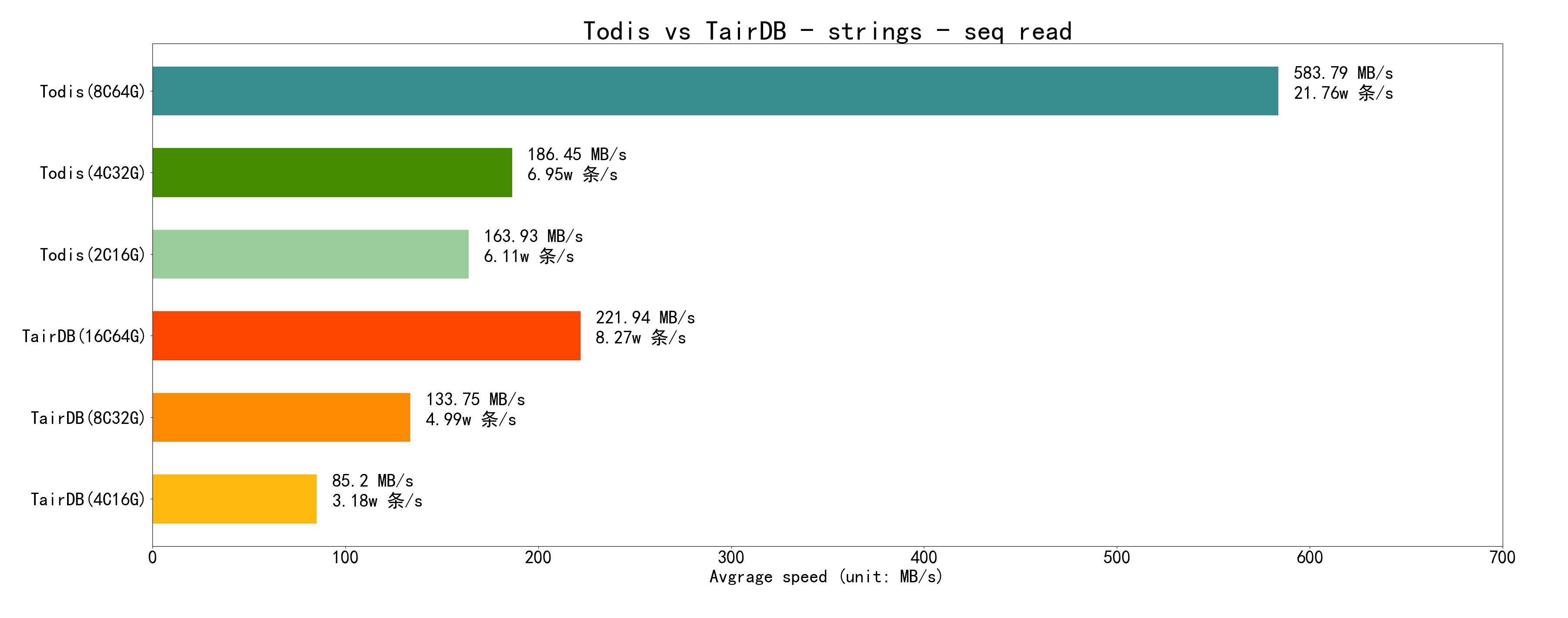
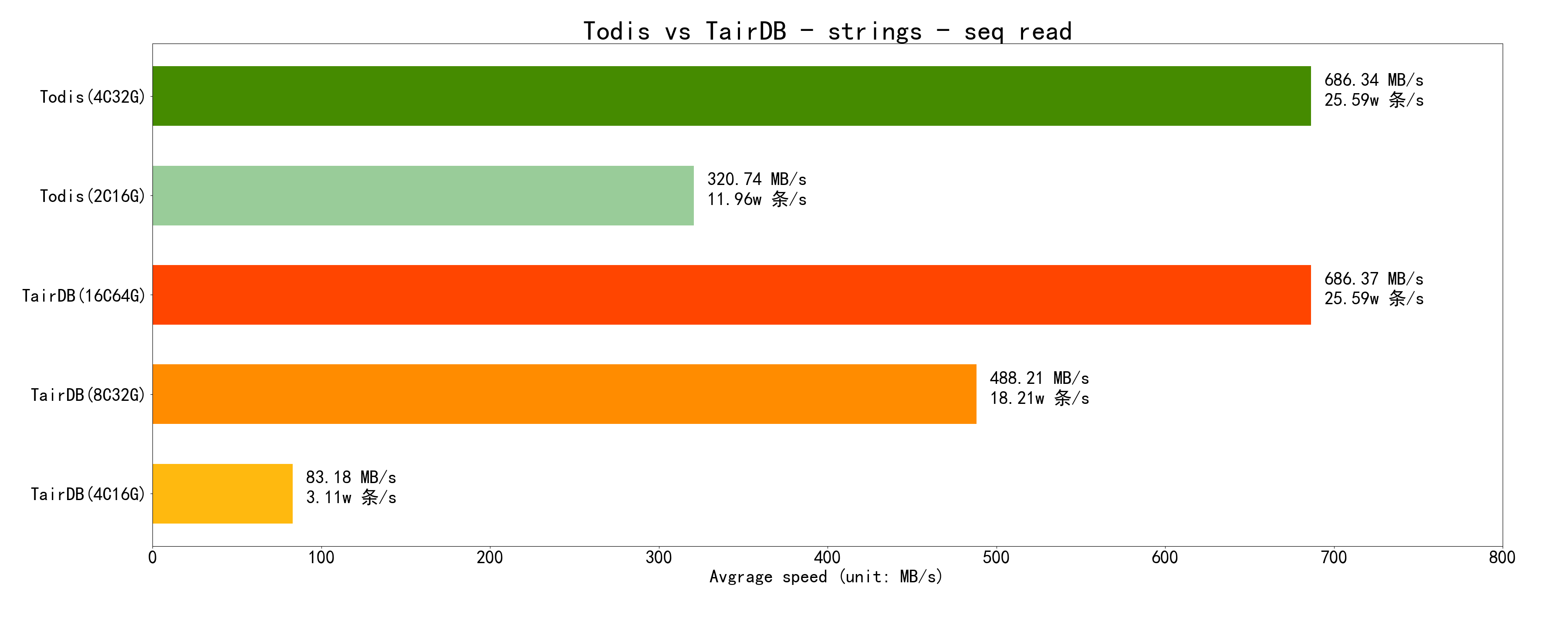
先看 顺序读:顺序读缓存命中率极高,所以性能都很好
再看 随机读:随机读缓存命中率很低,所以性能都比顺序读要差很多
5.2. 瞬时速度
每个时刻的瞬时速度,我们用折线图来表达,其坐标横轴是时间,纵轴是瞬时速度。因为读写的数据量相同,Todis 速度快,很快就结束了,所以 Todis 横轴长度很短,Tair 的横轴长度很长。
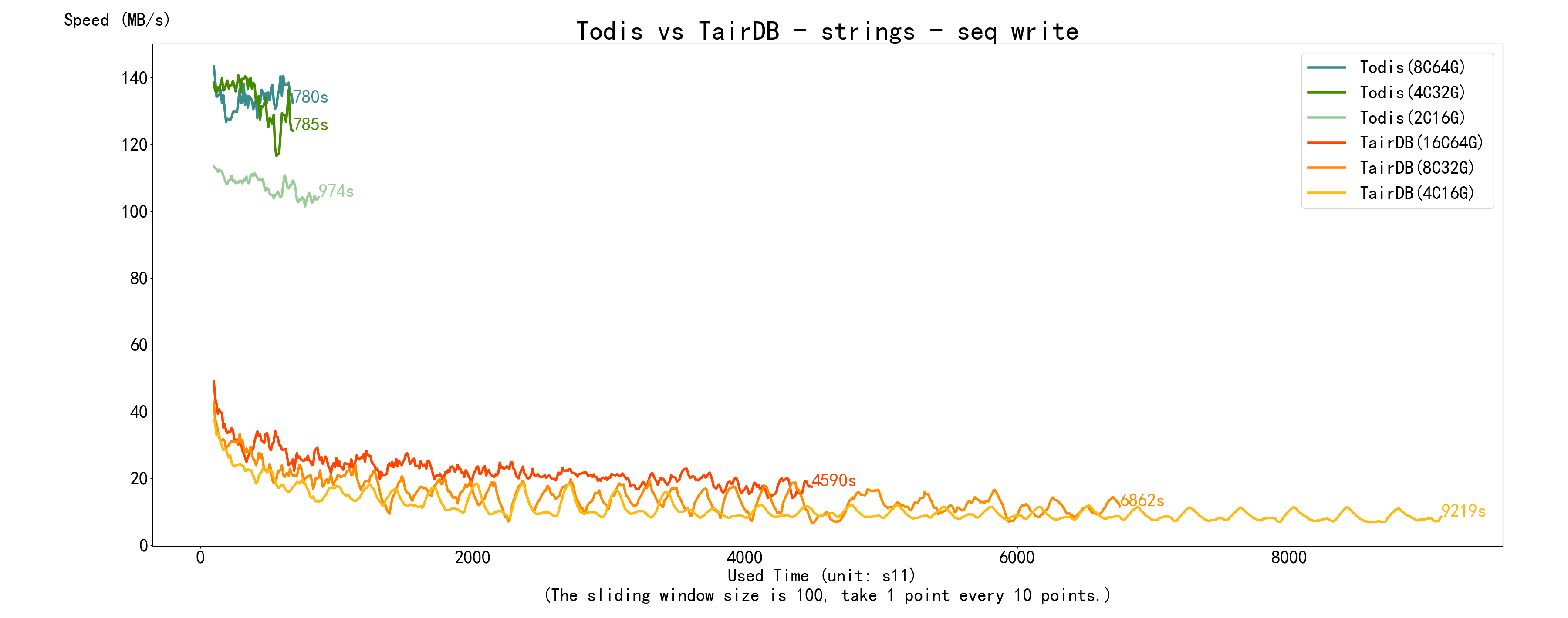
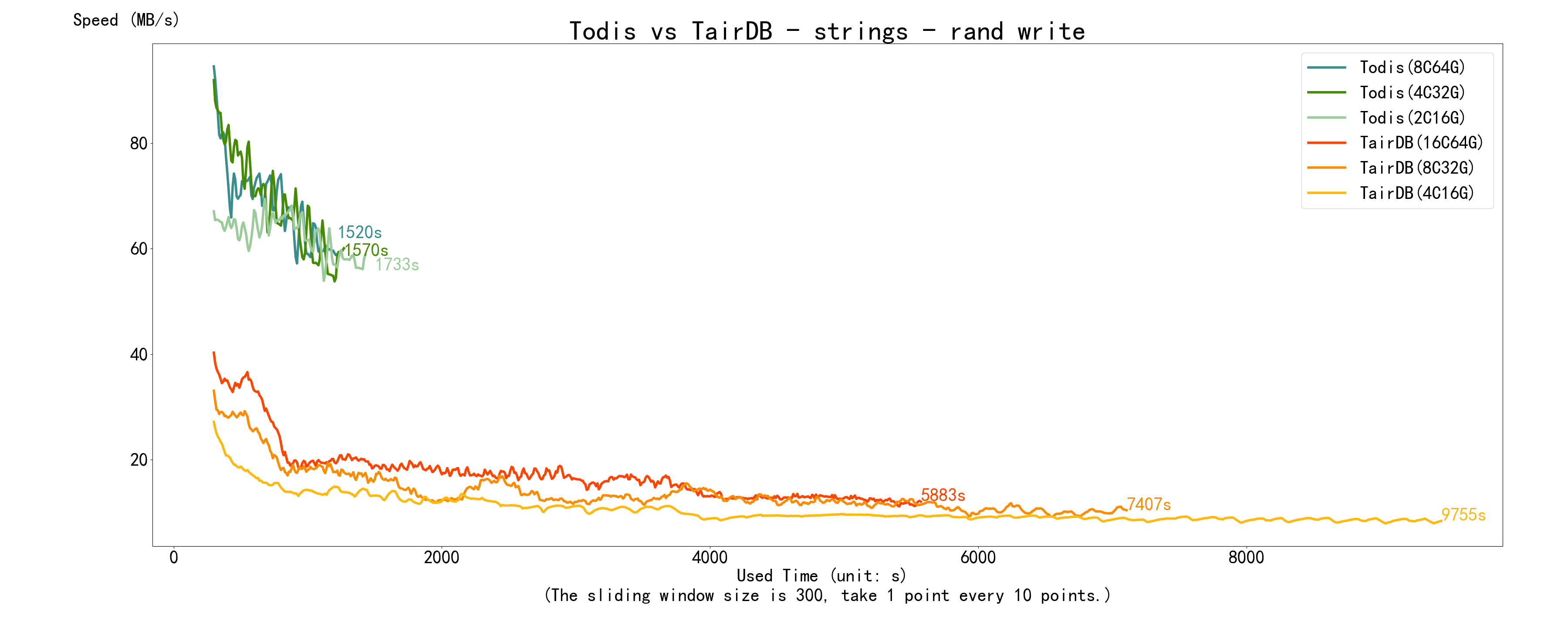
5.2.1 写数据
写数据 Todis 和 Tair 都有是先快后慢,并且有一定的波动,其中低规格 Tair 波动的周期性非常明显。
先看 顺序写
再看 随机写
5.2.2 读数据
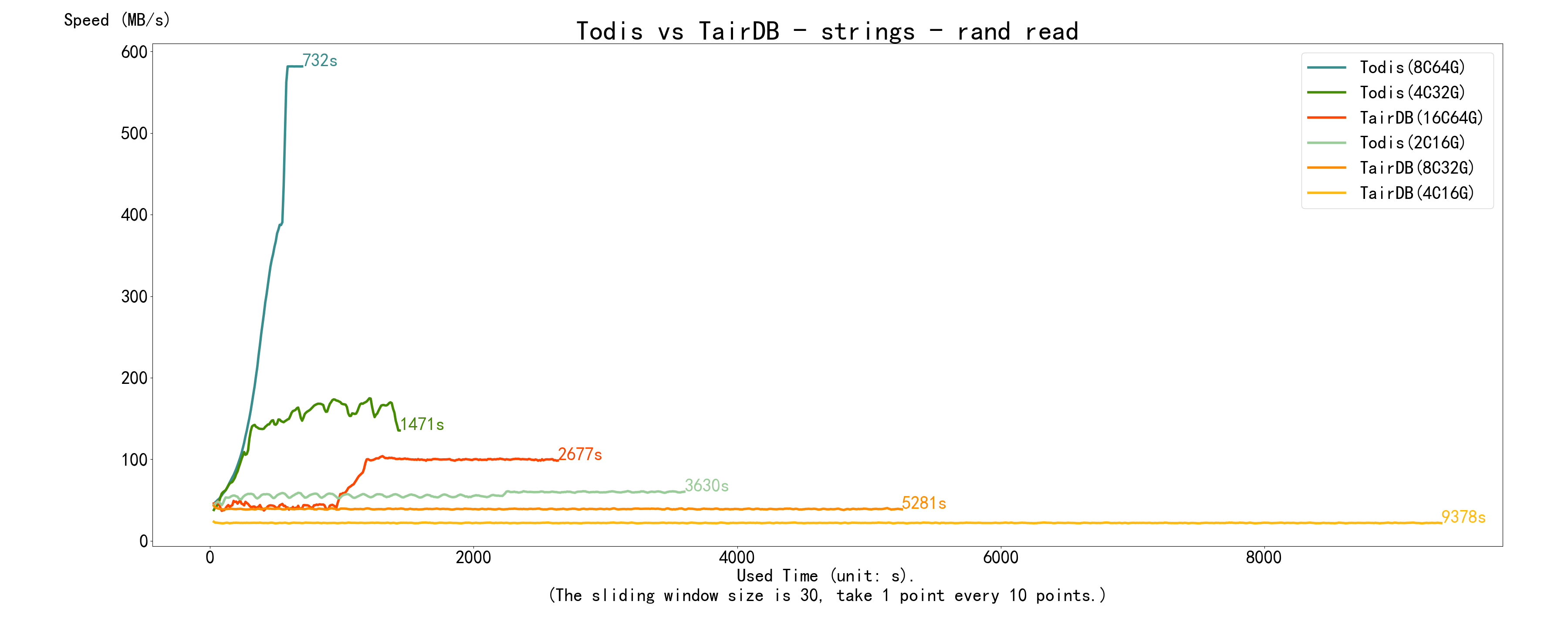
读数据用的是 mget,记录了循环读两轮的结果,即下面是读整个数据库两遍的数据。
- Todis 在读取测试之前清空了操作系统 Cache,从而相当于是冷启动的,并且关闭了操作系统预读(madvise random)
- Tair 没有提供清空 Cache 的命令,也无法登录 Tair 机器去清空 Cache,相当于是热启动的,合理猜测 Tair 应该也关闭了预读
先看 顺序读:图中 Todis 8C64G 规格在横轴 500 多秒处有个突发的跳跃,这是因为第一遍读取结束以后,所有数据都装进了缓存,第二遍读取时缓存全部命中,所以性能极高,表现在折线图上就是一个突发的跳跃。另一个有趣的点是在跳跃点之前的速度非常稳定,这是因为顺序读的时候,Cache 命中率是稳定不变的(每次加载一个 4K Page,包含 4~5 条数据,命中率就是 70~80%),从而其性能就和 IOPS 一样稳定了。

再看 随机读:图中 Todis 8C64G 的跳跃点在视觉上比顺序读要靠前很多,但其实也是在横轴 500 多秒处的(因为横坐标的最大值变大了 4 倍)。真正的不同是其在跳跃点之前的部分相比顺序读是逐渐提高的,这是因为数据总量有限,冷启动随机读的时候 Cache 命中率是逐渐 提高(一阶导数) 的,并且随着 Cache 的填充,Cache 命中率 提高的速度(二阶导数) 也是逐渐加快的。
6. 热数据对比读测试结果
该对比测试中不包括 Todis 8C64G 的规格,因为 8C64G 可以将全部 109G 数据都装入内存(采用内存压缩技术),就没有必要进行此项对比了。
- 实际上,如果写完数据再执行一次手动 Compact,Todis 4C32G 的规格也可以将全量数据装入内存
- 在真实业务中一般不会频繁执行手动 Compact,所以我们该测试中我们没有这么做
- 对于真正有需要的业务,手动 Compact 可以大幅提升性能
在真实的业务场景中,数据有冷热之分,这也是我们之所以选取 Todis 或 Tair 的理由,在该测试中,我们将一部分数据作为热数据进行测试,下表中热数据占比是相对于全量数据的百分比:
| 数据库 | 规格 | 热数据占比(顺序读) | 热数据占比(随机读) |
|---|---|---|---|
| Todis | 4C32G | 40% | 10% |
| Todis | 2C16G | 20% | 5% |
| Tair | 16C64G | 40% | 10% |
| Tair | 8C32G | 20% | 5% |
| Tair | 4C16G | 10% | 3% |
5.1 平均速度
先看 顺序读
再看 随机读:Tair 16C64G 的性能比 Tair 8C32G 的性能高了十几倍,从这里可以推断出来,16C64G 可以将全部热数据都装入内存,而 8C32G 无法将全部数据装入内存,再进一步推断:按照热数据的数据量,32G 是可以轻轻松松装下 5% 的热数据的,为什么这个性能结果却显示没有装下呢?这是因为 Tair 中 RocksDB 的 BlockBasedTable 中,一次 Cache Miss 在加载有效数据的同时,还会引入很多无效数据,如果 BlockSize 设置得较大,加载的无效数据就会过多,这些无效数据占用了宝贵的 Cache 空间!